1. Purpose
My goal in compiling the tips and tricks I’ve learned into Effective Software Engineering (ESE, pronounced “easy”) is to help spread my knowledge, experience, and mistakes, to a broader community that more than likely may not have formal software engineer training. But don’t let my tips and tricks fool you, there are exceptions to every rule. Effective Software Engineering is not meant to be a strict set of rules that guarantee success. Software engineering is just like any other science or engineering discipline in that many decisions require a careful balance of the advantages and disadvantages to one, two, three, or more solutions. The tips and tricks here are general concepts that will improve the project or code you are working on or improve your software development expertise. These suggestions are based purely from my previous experience that I have found beneficial on a non-trivial number ofoccasions.
I want to spread my knowledge, experience, and most importantly my mistakes. A lot of times a well-engineered solution takes time. A lot of time. There is time spent on designing what the code will look like, meaning what classes/object will be created and what will they do and not do. There is time developing interfaces, both externally facing and internally facing interfaces and how they interact with other bits of code. There is time spent on implementing the code, making sure the code does not have “feature creep” or have the potential for feature creep. And lastly, the most time spent in a solid software solution is in the testing. Ideally there should be unit tests, integration tests, and high- level system (or end-to-end tests). Although everyone can agree that comprehensive testing is good, the amount of testing that actually takes place is almost always less than comprehensive. This results in bugs found during operational processing rather than in a controlled development or testing environment.
Most tips and tricks discussed here are meant to be “quick wins”, meaning each recommendation should take less than a week to implement and test, and in some cases just a few minutes. These quick wins are things I’ve compiled over the years as a way to defensively protect the code before bugs are discovered during testing, you might even consider them to be good habits. I’ve certainly made my own mistakes that have caused bugs in production environments. But by making these mistakes I’ve matured as a developer who can now spot areas that will cause problems in production environments.
Another reason why I am creating ESE is because a formal software engineering project can be a big and complicated endeavor, but it does not have to be! A formal process that is agreed upon by all developers, managers, customers, and everyone in between can be a really powerful tool. However I want these quick wins to help spread the word that good software doesn’t have to be created by someone with formal software engineering training on a team of only software engineers. Anyone can learn to write code, learning to write great bug-free code takes a bit more effort. Formal training helps, but it is not absolutely required. Hence I am giving you my secrets in hopes that you too can learn from my mistakes and build bug-free code!
And lastly, always think about the future of the code rather than a strict process. In my experience, the code will outlive the developer. At any given time, new members join a software project and old members leave. The code stays around making new team members inevitably responsible for the mistakes of their predecessors. It is important for both new and veteran team members to constantly think about what is best for the project. Can I just slap together a little script and push it into the production system? Possibly, but I really shouldn’t. The script should be well thought out, various edge cases should be accounted for, and testing should be automatic and repeatable. Without this, bugs will rear their ugly head at the worst possible time.
2. Feedback!
Effective Software Engineering is and will be a living document. I will periodically add more tips and tricks that may or may not be fully proof read, or fully account for every possible use case. In such a scenario where you find errors, discrepancies, boundary or edge cases where my tips and tricks break down, please let me know. I want to hear from you (Mattermost, RocketChat, email, even Skype), especially if you have something to teach me!
3. Terminology
The target audience for Effective Software Engineering is mainly for people who have stumbled upon the practice of writing code but do not necessarily have formal software engineering training. Given that audience, there will undoubtedly be unfamiliar terminology that should be understood completely before continuing. This page is set up to enumerate as much terminology as possible that Effective Software Engineering will use. As Effective Software Engineering grows, this page will appear to be a living document as more terms get introduced periodically.
The terminology enumerated on this page contains both software engineering specific terms and terms used to describe common aspects/scenarios of software engineering practices.
3.1. Coding
| Term | Definition |
|---|---|
| Pseudo-code | Code that does not follow a specific language syntax, but does convey a specific sequence of events. |
3.2. Languages
The terms function, method, procedure, subroutine, and other synonyms, all generally mean the same thing. They are smaller encapsulated bits of logic that may (or may not) accept input variables, perform some computation, then may (or may not) return a value.
In all practicalities, the difference between these definitions are arguable at best. Many languages, particularly object-oriented languages, consider a method different in that it operates on a specific instance object. In Java this is the “this” reference, while in Python this is the “self” reference. Functional programming languages like to use the term “procedure” for indicating the function does not have any side effects. In general I will stick to a convention whereby a “method” implies some sort of object-oriented aspect and the other terms do not. Within the context of Effective Software Engineering, these terms are mostly interchangeable.
3.3. Roles
These roles are not mutually exclusive. For example, a developer could also be a sustainer, or a sustainer could also be a tester. These are intended to be more of a logical separation of duties rather than a physical separation of people.
| Term | Definition |
|---|---|
| Developer** | The person whose job is to write code. |
| Sustainer | The person whose job is to monitor or maintain operational instances of code. |
| Tester | The person whose job is to test code written by a developer. |
** For the purpose of Effective Software Engineering, the terms “developer”, “coder”, “programmer”, “software developer”, and “software engineer” are all synonymous with each other. It is arguable at best that each of these terms have separate definitions, so any references to any of those terms are intended to mean “developer.”
3.4. Testing
| Name | Synonyms | Authors / Maintainers | Description |
|---|---|---|---|
| Unit Testing | White-box Testing | Software Engineers | Unit tests typically validate the implementation of objects or modules. A change to the implementation has a high chance that a unit test will fail afterwards. Additionally, unit tests should not depend on the whole-system functioning to run the test, they will use fixed values, known test data, and/or mock objects to exercise a specific object or module. |
| Integration Testing | Black-box Testing | Software Engineers | Integration tests exercise higher level functionality whereby groups of objects or modules are clumped together for testing. A lot of times integration tests are exercising functionality at the interface level. A change to an implementation should not usually break an integration test. |
| System Testing | Black-box Testing | Test Engineers | A level even more abstracted, than integration testing, from the specific implementation details. At this level system tests usually pool together multiple applications, databases, and other external entities for testing that comes close to if not exactly like production environments. |
In my experience, very large software projects will have a software development team that writes the code then performs both unit and integration level testing, and a dedicated Test Engineers perform the system testing. It is not unheard of for developers to perform system testing, nor for Test Engineers to dabble in lower level tests, but if a project grows to the point where dedicated Test Engineers are employed then they will more often than not stick with very high level system testing.
4. References
4.1. More Variety
Even though my Effective Software Engineering utilizes Java and Python for example code, many of these tips and tricks focus on the higher level understanding of a concept which could be applied to many other programming languages like C, C++, JavaScript, Ruby, or any other language your project uses. Therefore, here are just a few more resources you can use to develop stronger and more robust software solutions and team practices. These are resources that I stand by, resources that I continue to use periodically.
4.2. By Language
TODO Build these references into links!
4.2.1. C
- 21st Century C
- C Programming Essentials
- Intermediate C Programming
4.2.2. C++
- Effective C++
- Effective Modern C++
- Effective STL
- More Effective C++
4.2.3. Java
- Effective Enterprise Java
- Effective Java
- Logback
4.2.4. Javascript
- Effective Javascript
4.2.5. Python
- Effective Python
4.2.6. R
- Effective R Programming
4.2.7. Team Methodologies
- Effective Dev-Ops
- The Scrum Field Guide
4.2.8. Other Software Engineering Topics
- Working Effectively with Legacy Code
5. Example Code
In these tips and tricks I try to provide most examples with code written in Java and Python demonstrating the topic in a trivial way. There are a select few examples that have sample code written in C/C++, but those cases are for very niche topics – so one may argue the choice of language can play a part in the overall outcome.
I truly believe one of the best ways to learn something new is to take something that works, break it, then figure out a way to make it work again. Because of this philosophy, each example will be complete in that compiling and running the sample code should produce non-erroneous output – assuming you have a proper development environment set up for the language. This does make the example code a bit lengthy, and does add extra fluff like import statements, but I believe it should be easy for you to have a play with the code. Change it, break it, fix it. If nothing else, question it.
To make things even easier, all of the example code is supplied in a few Gitlab projects with README files that detail how to set up the project and run the sample code. These Gitlab links have also been included in the “Space Shortcuts” on the left.
“go easy-cpp” “go easy-java” “go easy-python”
I also try to avoid as much as possible the requirement of third-party libraries. However, for certain tips and tricks it may be required that you have a working development environment to import such a library. With regards to Java, the Gradle build.gradle script defines all extraneous libraries. Running any Gradle build command should pull down the necessary dependencies assuming Gradle was configured with a custom mirror. With regards to Python, I supplied a simple setup.py script that will install the dependencies for you via pip3.
5.1. Language Requirements
For the most accurate documentation, each project’s README.md file documents the exact development environment required to run the sample code. But generally speaking:
-
The C/C++ project depends on CMake version 3.5 or above on your
$PATH. -
The Java project requires a JDK version 11 pointed to by your
$JAVA_HOMEvariable. In addition, the Java project uses Gradle as the build and dependency management system. You will need a version of Gradle version 2 or version 4 (but preferably something recent) on your$PATH. -
The Python project requires python3 and pip3 on your
$PATH. This project also supplies a setup.py script to make Python dependency management even easier. When you pull down the repository, make sure to run the script to enable any third-party dependencies the same code requires.
5.2. Language Choices
In all of the ESE example code projects I have decided to use relatively recent versions of their respective languages. It is very possible to port the examples to older versions, however I would rather focus on the concept each tip/trick is trying to convey rather than the implementation of a particular example. In my opinion, any new code should be written against a recent but stable language version. However there are valid use-cases that absolutely require previous versions, and so I leave it up to the reader to back-port any examples they may find useful in the older standards. I do not perceive that as a challenging exercise, but if you do run into particularly difficult issues I am more than willing to help resolve any back-porting you may endeavor.
5.2.1. C/C++
In many topics the Java and Python example code will suffice. There are however a few niche topics where one may argue the choice in language is important, and getting as “close to bare metal as possible is required.” I do not believe that argument holds up in many cases that it is used, so I do have a few topics that dispel that myth with actual C/C++ examples.
Suffice it to say, the C/C++ project will not get very large as it will only have code from very niche topics.
5.2.2. Java
The Java example code provided in ESE was written with a Java 11 development kit. It is possible to tweak the code to support earlier versions of Java, however I decided to stick with this version of Java since it provides developers with more features and utilities to make many examples shorter and more concise. And with Java’s fast release cycle, the minimum version of Java required to run the examples will periodically be upgraded.
Also, Java is typically used in Object-Oriented (OO) projects. Since I will make example code short and concise the Java code may not use many OO design principles as that would add extra noise to what I’m trying to get across. In many cases I will choose to convey a particular topic with simple methods and functions than an OO design.
5.2.3. Python 3
The Python example code in ESE was written with a Python 3 interpreter. The main reason why I chose to provide examples in Python 3 was because Python 2 is no longer in active development. Python 2.6 was the last version to genuinely have new features, and Python 2.7 was created as an interim version that back-ported several Python 3 features to Python 2. The idea was that Python 2.7 will help ease the pain when converting a project from Python 2 to 3. I should not even have to say this, but unfortunately there are still many Python 2-only projects running around. Hopefully ESE puts pressure on them to upgrade their compatibility with Python 3.
Lastly, there are multiple implementations of Python that are generally compatible with one another. CPython and Jython are among two industry standard implementations. CPython is the official implementation with the interpreter written in C, while Jython is another popular Python implementation but the interpreter is written in Java. In many cases, it might not matter which implementation you are using, but it is very important to know the strengths and limitations of the interpreter you decide to use because your application or script may genuinely behave differently between the two. The examples and descriptions provided in ESE were tested with CPython.
6. Upcoming Topics
There are many, many, topics that I have not yet created content for. I will be creating so much more tips and tricks in the future, most of which I already have an idea of what I want to share while other tips and tricks just have not yet popped in my head yet. So please watch this space to receive email notices when I publish new topics!! Or if you’re interested in a particular topic, shoot the idea by me and I’d be more than happy to add that to the top of my queue.
- Collaboration
- Code Reviews
- Configuration Files
- File Formats
- Prefer Configuration Files over Code
- Version Control Configuration Files
- Databases
- Examples
- MongoDB
- SQLite
- SQL vs. NoSQL
- Examples
- Development Tools
- IDE vs. CLI
- Build Tools for Java
- Gradle
- Maven
- Nexus
- Build Tools for Python
- Distutils and Setuptools
- Design
- “Anti Patterns”
- “Design Patterns”
- Decorator Pattern
- Null Object Pattern
- Singleton Pattern
- Encapsulation
- Global Variables
- Immutability
- SOLID
- Stateless Code
- Embrace the Language
- Coding Style and Standards
- Language Supplied Utilities
- Software Reuse!
- Error Handling
- Exception Handling
- Library Exceptions API
- Signal Handling
- Using “null”
- Interfaces
- External Facing Interfaces
- Internal Facing Interfaces
- Inter-Process Communication
- Data Formats
- RabbitMQ
- Sockets
- Memory Management
- Memory Leaks
- Strong vs. Weak References
- Methodologies
- Scrum
- Test Driven Development
- Waterfall
- Myths
- Python Threads are Useless
- Optimizations
- Profiling Java
- Profiling Python
- Programming Paradigm
- Functional Programming
- Object Oriented Programming
- Releasing Software
- Building Deliverables (zip, rpm, deb, Docker images, etc…)
- Semantic Versions (SemVer)
- Security
- Hard Coding Cryptographic Keys
- Protecting Against Database Timing Attacks
- Storing Passwords
- Testing
- Continuous Integration
- Integration Testing
- Mock Objects
- User Experience
- No Good $HOME
- Callbacks
- Serialization
- Systemd Files
- Variable Arguments
7.1. Git

Git is the Perl of version control.
– ESE Author.
something
echo testing
8. Concurrency and Parallelism
8.1. Description
Effectively decomposing a problem so it can utilize multiple threads or multiple processes requires fully understanding a few concepts. One of which is the difference between concurrent and parallel processing. The two are not equivalent and thus erroneously choosing the wrong paradigm could cause degradation in performance. In the worst case scenario this may send developers down a rabbit hole while trying to find ways to optimize the code.
8.2. Definitions
A job is the work that needs to be done on the smallest and independent chuck of data. Meaning the processing of the data should not rely on any kind of previous processing in order for multiple jobs to run together. For example, it would not be wise to implement a Fibonacci sequence calculator since each “job” requires knowledge of all data points. Alternatively, if you need to multiply by a scalar each element in a sequence of numbers, then this can be performed in parallel or concurrently since “job” only requires a single data point. For this article you can think of a “job” as a thread or process running on the CPU.
A context switch is the phrase to describe the procedure in which the operating system changes which job’s instructions get executed on a CPU’s core - said in other words, a CPU’s context (i.e. the CPU registers) is switched from one job to the next. Deep in the hardware level, this is where the registers and caches on the CPU are saved into RAM and another job’s state is created or restored into the CPU’s registers and cache. After which, a job can start or safely resume instructions exactly where it left off previously. Hardware in conjunction with the operating system can make this very quick, but it is still a non-free consumption of time. The operating system will try to reduce context switches as reasonably possible while still providing a fair amount of execution time across all waiting jobs. Regardless of a concurrent or parallel paradigm, context switches happen every time a job starts and stops executing on the CPU.
Concurrent processing is when a computer can perform multiple actions seemingly at the same time. Single-core CPUs can only perform concurrent operations because they physically do not have the hardware to perform two actions simultaneously. The operating system will run a program’s instruction on the CPU for a particular chunk of time. The operating system will then halt the program either when the time slice expires or when the program freely signals to the operating system it does not need the CPU for a relatively long amount of time, like slow I/O requests or explicit “sleep” or “wait” instructions.
Parallel processing is when a computer can actually perform multiple actions simultaneously. Multi-core CPUs have the ability to run programs in parallel. In the early days of multi-core systems, a single process can only run on a single CPU at any given time. But as hardware and software progressed, matured, and became more efficient, it is now possible for processes to run multiple threads on multiple CPUs simultaneously.
A process is the realization of an executable file from the hard disk. Simplistically, the operating will copy the executable file into memory and start executing the bytes of the file on the processor. A thread can be modeled in a way very similar to a process (e.g. execute an instance of code) but is encapsulated within a process. Because all threads live within a single process, they all share the same allocated resources the operating system gave the process. That includes all allocated memory, file descriptors, signal handlers, etcetera. It is not terribly important if you’re not familiar with all of those terms, but just keep in mind a “resource” allocated to one process is technically shared with all threads in that process.
8.3. Visualization
To better visualize the difference between concurrency and parallelism, let us take the following scenario as an example.
In this example there are four jobs: green, red, blue, and grey. Each job needs to perform some operation that will require 5 milliseconds of time on the CPU. The operating system could decide to execute the jobs linearly, as such:

The problem with this model is that three of the four jobs are starved CPU time. The grey job has to wait 15 milliseconds before it can even start. This problem is exaggerated even further when jobs run for much longer than a few milliseconds.
Scheduling algorithms in modern operating systems are smarter than this. The operating system will try to determine a fair and, close to optimal, way of giving each process some CPU time.
Assuming there is no overhead costs with context switching, let us pretend the operating system will give each job these time slices on the CPU:
- The green job runs for: 2ms, 1ms, then 2ms.
- The red job runs for: 1ms, 1ms, 2ms, then 1ms.
- The blue job runs for: 3ms, then 2ms.
- The grey job runs for: 1ms, 1ms, 1ms, then 2ms.
In a concurrent system the four jobs will be executed on the CPU as such:

As you would expect, the total time to execute all four jobs still takes 20 milliseconds. We did not get to complete all of the jobs any faster, but each job had the chance to start sooner at the expense of finishing a bit later. You might wonder why might any one want to ever use this scheme. For the decades when computers only had a single core CPU this is how all programs ran on the CPU. Think about it, a computer mouse needs a driver to interpret the signals from the mouse into real coordinates. Or a keyboard needs a driver to translate various signals from the many types of keyboards into character-codes. A monitor needs even more software to take the raw graphics and turn on the pretty little pixels inside a monitor. We cannot possibly expect a computer to do each of these operations in a contiguous manner. Each of these drivers need time on the CPU to reach the end goal of displaying a mouse roll over a link, or print characters in a word processor.
While a concurrent approach can only use a single core on a CPU a parallel approach will utilize multiple cores of the CPU. For simplicity, let’s say the operating system’s algorithm for choosing a CPU for a job is the “round robin” approach. Each new job that is created will use the next CPU in the sequence, then loop back when the number of CPUs has been exhausted. For our four job example, the green and blue jobs will run on CPU #1 and the r ed and grey jobs will run on CPU #2. Running the jobs might look like this:
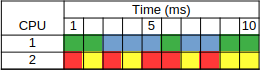
In the parallelized case we cut the total time in half. All jobs will be complete within 10 milliseconds.
8.4. Application
All of this is to say developers should understand how processes and threads work for the language they are writing in so they can write code effectively. If a developer assumed their code is running in parallel but in fact was running concurrently they may spend a needless amount of time debugging a “code takes too long” problem. Conversely, if the developer assumed the code was running concurrently but in fact ran in parallel they may spend an equally needless amount of time debugging the elusive “race condition” that only sometimes appears.
8.4.1. Java (Threads are Parallel)
It is rather difficult to implement a truly concurrent processing in Java. For all intents and purposes, threads in Java run in parallel to one another. The Java virtual machine and the operating system will run a single process’ multiple threads on multiple cores.
8.4.2. Python (Threads are Concurrent, Processes are Parallel)
Python takes a different approach than most other languages, specifically the
CPython implementation whereby threads will run concurrently and processes will
run in parallel. In most other languages both processes and threads run in
parallel. Again, this is not the case for CPython. For historical reasons, the
memory model inside the CPython implementation had not been designed to handle
parallel processing safely and thus the Global Interpreter Lock (a.k.a. GIL) was
created. When a thread begins or resumes execution it locks the GIL which will
effectively prevent any other threads from running simultaneously even if the
hardware has multiple cores. To work around the GIL in a parallel manner, you
must run code within multiple processes. The Python multiprocessing module
makes this incredibly easy, but it does have draw backs that will be discussed
on separate pages.
This does not make Python threads unsuitable in all cases, I will discuss on a separate page where Python threads can be used efficiently.
8.2. Inter-Thread Communication
8.2.1. Quick Tip
Use existing thread-safe queues for inter-thread communication.
8.2.2. Description
The concept of communication between multiple threads (or in the case of Python, multiple processes) is a very common scenario in parallel and concurrent applications. One thread or process produces data while another thread or process consumes that data. And in many cases, there could potentially be multiple producer threads or processes (in a thread/process pool) and there could potentially be multiple consumer threads or processes (again in a thread/process pool). This scenario is common and usually solved by interfacing the two threads or processes with queue.
The simplest approach to this scenario is to use a thread/process safe blocking queue, one that typically comes from the language’s standard library. In both the Java and Python example code, I am using a thread-safe blocking queue that acts as the interface between a single producer thread to a single consumer thread. It would be very easy to adapt the example code to have multiple producers and/or multiple consumers, but for simplicity there is only one of each.
What makes this solution so powerful is the queue’s ability to block based on how many messages are currently sitting in the queue. For producers, the queue will block when it reaches its maximum capacity. Since there is no more room for another message on the queue the queue will wait until space is available. For consumers, the queue will block while the queue is empty and only return a message when a producer thread puts an object onto the queue.
In both the Java and Python API for queues there is the option to supply a timeout associated with each blocking call in the scenario where you want to block but no indefinitely.
In the case of Java, there are various Queue implementations that could squeeze out better performance from the application. There are blocking queues, non-blocking queues, queues backed by arrays, queues backed by linked-lists, and even priority based queues.
8.2.3. Examples
8.2.3.1. Java
// javac InterThreadCommunication.java
// java -cp . InterThreadCommunication
import java.util.Objects;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class InterThreadCommunication {
private static class Consumer {
private final BlockingQueue<Integer> queue;
private final Integer sentinel;
private Consumer(final BlockingQueue<Integer> queue,
final Integer sentinel) {
this.queue = queue;
this.sentinel = sentinel;
}
private void consume() {
System.out.println("Consumer: started.");
try {
for (Integer i = queue.take(); !Objects.equals(i, sentinel); i = queue.take()) {
System.out.println("Received: " + i.toString());
}
} catch (final InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("Consumer: finished.");
}
}
}
private static class Producer {
private final BlockingQueue<Integer> queue;
private final Integer sentinel;
private final int messageCount;
private Producer(final BlockingQueue<Integer> queue, final Integer sentinel,
final int messageCount) {
this.queue = queue;
this.sentinel = sentinel;
this.messageCount = messageCount;
}
private void produce() {
System.out.println("Producer: started.");
try {
for (int i = 0; i < messageCount; i++) {
queue.put(i);
}
queue.put(sentinel);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("Producer: finished.");
}
}
}
public static void main(final String[] args) throws InterruptedException {
System.out.println("Main: started.");
final int messageCount = 25;
final BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(messageCount / 5);
final Integer sentinel = Integer.MIN_VALUE;
final Consumer consumer = new Consumer(queue, sentinel);
final Producer producer = new Producer(queue, sentinel, messageCount);
final ExecutorService threadPool = Executors.newFixedThreadPool(2);
try {
threadPool.execute(consumer::consume);
threadPool.execute(producer::produce);
} finally {
threadPool.shutdown();
threadPool.awaitTermination(10, TimeUnit.SECONDS);
System.out.println("Main: finished.");
}
}
}
8.2.3.2. Python
#!/usr/bin/env python3
# python3 ./InterThreadCommunication.py
import multiprocessing
import queue
# The number of messages to produce/consume.
MSG_COUNT = 25
# The maximum size of the queue after which put() calls will block until space is available.
QUEUE_SIZE = int(MSG_COUNT / 5)
# The message to signify the consuming iterator should stop consuming.
SENTINEL = "STOP123"
def consumer(queue):
print("- Consumer: started.")
for i in iter(queue.get, SENTINEL):
print(f"- Received: {i}")
print("- Consumer: finished.", flush=True)
def producer(queue, max_count):
print("+ Producer: started.")
for i in range(max_count):
queue.put(i)
print(f"+ Produced: {i}")
queue.put(SENTINEL)
print("+ Producer: finished.", flush=True)
def run_as_thread_pool():
from multiprocessing.pool import ThreadPool
print("#" * 40)
print("Testing thread pool")
thread_queue = queue.Queue(maxsize=QUEUE_SIZE)
pool = ThreadPool()
pool.apply_async(func=consumer, args=(thread_queue,))
pool.apply_async(func=producer, args=(thread_queue, MSG_COUNT))
pool.close()
pool.join()
assert thread_queue.empty()
print("Thread pools done.")
def run_as_process_pool():
print("#" * 40)
print("Testing process pool")
manager = multiprocessing.Manager()
process_queue = manager.Queue()
pool = multiprocessing.Pool(processes=2)
pool.apply_async(func=consumer, args=(process_queue,))
pool.apply_async(func=producer, args=(process_queue, MSG_COUNT))
pool.close()
pool.join()
assert process_queue.empty()
print("Process pools done.")
if __name__ == "__main__":
run_as_thread_pool()
run_as_process_pool()